Cloud Distributed File System Benchmark
Cloud computing nowadays is the cornerstone for all the business applications, mainly because of the high fault tolerance characteristic of Cloud technology. High resilience and availability typical of cloud-native applications are achieved using different technologies considering all aspects of Cloud services, among them reliable and distributed storage is one of the main feature to take into account. The concept of storage is tightly tied to the concept of the file system. The exploitation of a Cloud Distributed File System (CDFS) in a complex architecture, such as an Infrastructure as a Service (IaaS) cloud environment, leads to a stable and reliable system, which helps the cloud provider to achieve fault tolerance and to avoid all problems regarding storage for all purposes.
Our work goal is to provide an innovative comparison of CDFS. The originality of our comparison relies on four characteristics. The first characteristic is a qualitative comparison where all aspects related to CDFS characteristics are analyzed. The benchmark is designed and implemented considering a normal IaaS infrastructure as a use case. The second key aspect of our comparison is that it can provide a possible benchmark standardization guideline, identifying common parameters for future releases and new CDFS products. We believe that this benchmark could also be extended defining custom parameters and metrics. The third characteristic is that we provide extensive and fully expressive benchmark that covers all the possible aspects of an IaaS use case. The fourth aspect is the availability of a prototype for benchmark deployment and run, which can be used in order to test if a deployment is efficient
Cloud Distributed File System
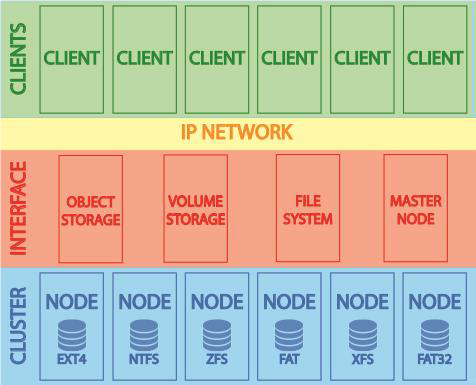
CDFS allow users to store and share data as simply as if the data were stored locally. In CDFS data can be stored on several nodes to guarantee replication for achieving better system performance and/or for achieving reliability of the system. Compared to TDFSs, in CDFSs data are more protected from a node failure. If one or more nodes fail, other nodes can provide all functionality. Files can be moved among nodes for achieving load-balancing. The users should be unaware of where the services are located and also the transferring from a local machine to a remote one should also be transparent. If the capacity of the nodes is not enough for storing files, new nodes can be added to the existing CDFS to increase its capacity by scaling horizontally.
Clients communicate with the CDFS using a network and must prove their identity, which can be done by authenticating themselves to an identity provider in the system. Encryption is one of the most important methods for providing data security, especially for end-to-end protection of data transmitted across networks. In distributed file system it is possible to use dynamic file replication that uses statistical information about files and servers. Data consistency can be achieved by using file locking.
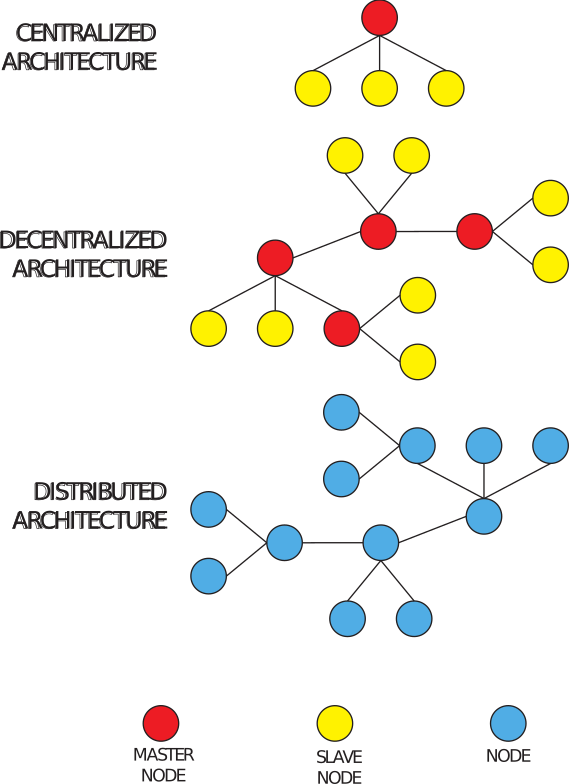
In order to have a clearer vision of how CDFSs work and to evaluate their pros and cons, we have decided to take an experimental approach consisting in deploying various types of CDFSs. The chosen parameters that drove our choice were diffusion, ease of use, importance, and architectural differences. Based on these criteria we have decided to choose Hadoop Distributed File System, GlusterFS, Ceph and XtreemFS. These CDFSs show a very important difference: the distribution of the nodes. In a distributed architecture the nodes can be distributed in various ways, each with its own pros and cons. HDFS has a centralized architecture (see top of Fig. 2) where a node (Master Node) manages and coordinates the other nodes of the cluster (Slave Nodes). GlusterFS has a decentralized architecture (middle of Fig. 2) where a series of nodes deal with the management and coordination of the other nodes. Finally, Ceph and XtreemFS have a distributed architecture (bottom of Fig. 2) where all the nodes are involved both in the management of the file system and in the management and coordination of the cluster. Fig. 2 shows all different architectures in terms of node hierarchy and distribution. In centralized and decentralized architectures, the red nodes are master nodes, i.e., nodes responsible of control and management decisions, while yellow nodes are the slave nodes responsible for managing the file system content such as files, objects and other relative data. The decentralized architecture instead relies on a multi-master environment and partitioned load and data distribution, defining also a protocol for master coordination. In distributed architectures, however, nodes have the same importance and decisions are made through the use of coordination protocols.
Benchmark
Our project consists in two different comparison:
- Non-Functional comparison: a qualitative comparison between architectures and functionalities offered by CDFSs
- Functional comparison: a full fledged performance benchmark taking into account IaaS operations as use case
Non-Functional comparison
Non-functional tests, consists in comparison between relevant characteristics that span several non-functional aspects, namely: POSIX API compliance, deployment support, usability, extensibility, consistency, and additional capabilities such as snapshot, stripping, and caching.
Our evaluation criteria was:
- Architecture
- Consistency
- Fault Tolerance, Replication, Striping and Caching
- Performance and stressing (from a non-functional point of view)
Functional comparison
Functional comparison consists in a benchmark performed with different tools in order to have full control of all undergoing operations. The tools are:
- Ganglia exploiting its reliable storage on a database and its complete web interface
- Inotify in order to monitor file system changes
In order to reflect a usual behavior of an IaaS platform (like Openstack) we made different tests. These tests are:
- Mean Write Time Test: the measurment of write time of different files with different size (changed every iteration of the test)
- Mean Write Propagation Time Test: the test measures how long the CDFS takes to become consistent propagating the write
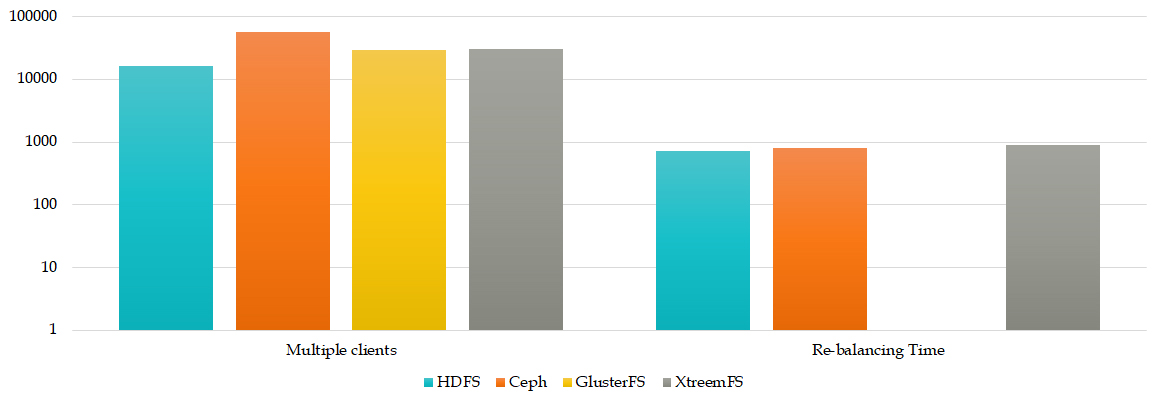
- Multiple Clients and Re-Balancing Time Test: measures the reaction time after a node failure for single CDFS and reaction time with multiple requests from multiple clients
Experimental Results
The obtained results shows that there are some differences between the four distributed file systems. Each of the four CDFSs ensures transparency and fault tolerance using different methods. Some differences emerged in the design; for instance, decentralized architecture allows scaling easier and faster thanks to greater load distribution. Another important point is the choice of using asynchronous replication, which allows managing a large amount of data more dynamically. About fault tolerance, it should be noted that all the systems have immediately noticed the fault (lack) of a node, but GlusterFS has not automatically proceeded to recapture the right number of replicas. In conclusion, this work has shown that in a cloud environment it is much more convenient to use CDFSs as they provide highly reliable and high availability features that should otherwise be implemented by hand over traditional TDFSs. Among benchmarked CDFSs, HDFS showed good performances when it is not necessary to save different data types, but there is the need of a simple and fast distributed file system. Ceph, instead, demonstrated to be very fast providing its support and benefits at the price of a few milliseconds.
Taking a further inspection into test results evidenced some interesting behavior, we will examine them in following sections
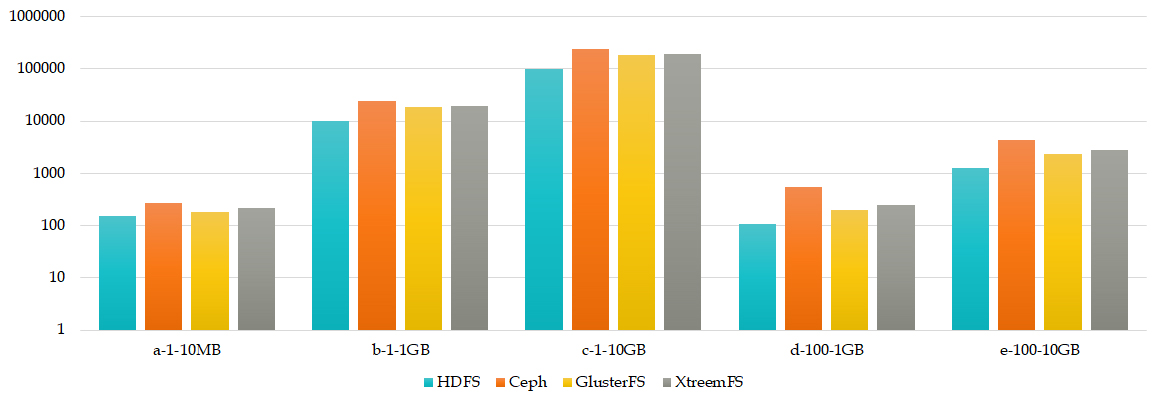
Mean Write Time
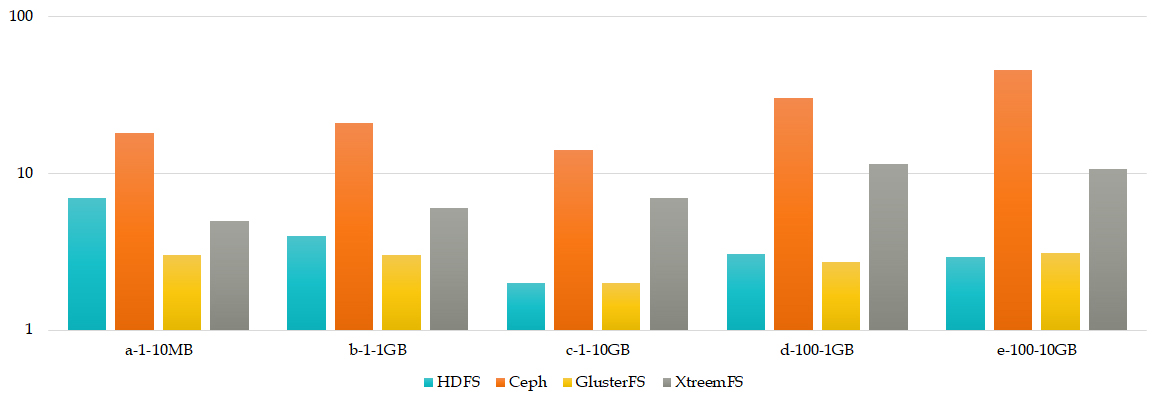
Mean Write time tests evidenced that Ceph is the slower CDFS for all tests, probably because of its complete distributed architecture, and HDFS is the fastest.
Figure 3 depicts the write time for each CDFS and file size.
Mean Write Propagation Time Test
Write Propagation times shows the Ceph's distributed architecture is the slower, instead GlusterFS has an update protocol really smart and slim.
Figure 4 shows the overall results with the differents CDFS and each file size tested
Multiple Clients and Re-Balancing Time Test
Regarding requests from multiple clients the results shows always Ceph as the slower CDFS but the gap is not so important.
Instead the re-balancing time shows a uniform time for all CDFS which supports this feature